HPC Information
HPC Information
BSCB Cluster Tutorial
This section is intended to guide you towards submitting jobs to the BioHPC cluster with minimal friction. If you haven’t used an HPC before, there will be a bit of a learning curve. However, the concept is simple:
- You login to one of the nodes on the server
- You setup a script with instructions for what you want the HPC to run
- You “submit” your script to the HPC and it adds it to a queue
- The “scheduler” on the HPC interprets the resources you’re requesting (CPUs, memory, time) and will run the script on one of the “compute” nodes when those resources become available
Useful Resources
- BSCB clusterguide
- Slurm introduction by Princeton ResearchComputing
- Introduction to slurm in the BioinformaticsWorkbook
- Slurm overview
- Slurm commands referencesheet
- Recordings of past BioHPCworkshops
Cluster structure
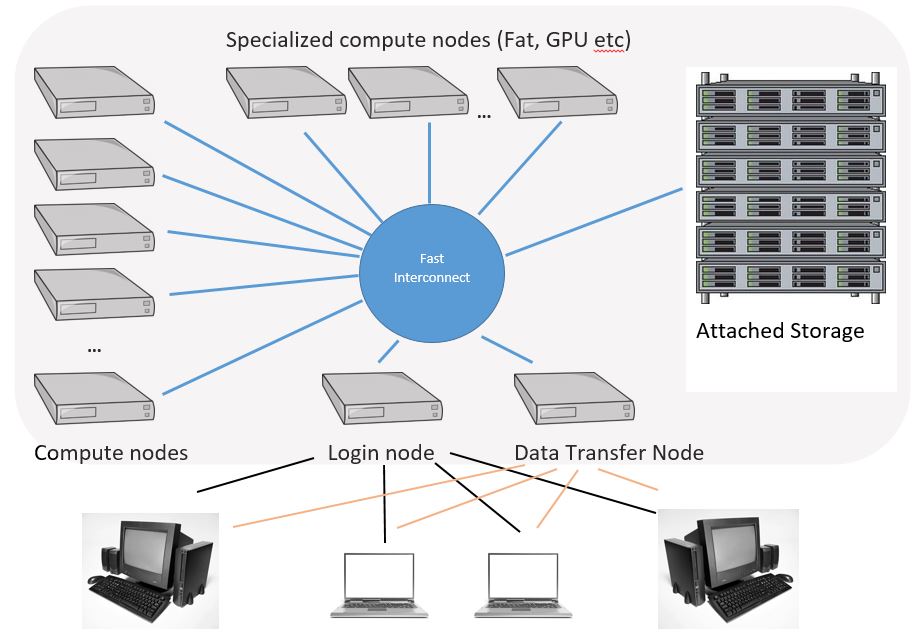
Job monitoring
sinfo: report the overall state of the cluster and queuesscontrol show nodes: report detailed information about thecluster nodes, including current usagescontrol show partitions: report detailed information about thequeues (partitions)squeue: show jobs running and waiting in queuessqueue -u abc123: show jobs belonging to userabc123scancel 1564: cancel job with jobID1564. All processesassociated with the job will be killedslurm_stat.pl cbsubscb: summarize current usage of nodes,partitions, and slots, and number of jobs per user (run on one ofthe login nodes)get_slurm_usage.pl: generate information about average duration,CPU, and memory usage of your recent jobs (run the command withoutarguments to see usage) - this may help assess real memory needs ofyour jobs and show whether all requested CPUs are actually used.